

Every week, another team ships an AI agent into production. And every week, the same things go wrong.
Credits disappear with no clear explanation. An agent starts giving subtly wrong answers and no one catches it for weeks. Usage drops off quietly after the first month. A latency spike hits during a board presentation. These aren't edge cases. They're the norm.
The uncomfortable truth is that the hardest part of enterprise AI isn't building the agent. It's knowing what's happening after you ship it.
Why This Is Urgent Right Now
We are past the era of chatbots answering FAQs. The agents being deployed today run multi-step reasoning across live enterprise data, call external tools, and inform real business decisions on pricing, customers and operations.
The stakes are different. A wrong answer from a static dashboard costs someone an hour. A wrong answer from an autonomous AI agent can propagate through a workflow before anyone notices.
At the same time, regulatory scrutiny around AI auditability is accelerating. "We have an AI" is no longer enough. Boards and compliance teams are starting to ask: can you show me every decision it made, and why? Can you prove it stayed within budget? Can you demonstrate it's being used - and used correctly?
Most teams cannot answer those questions today. And the gap between "deployed" and "operated" is where trust breaks down.
Enter Snowflake Intelligence - and the Speed Problem It Creates
Snowflake Intelligence is an enterprise intelligence agent that makes organizational insights accessible to every employee through natural language, letting them uncover the "why" behind every "what," all within Snowflake's secure and governed perimeter.
Cortex Code accelerates this further. Unlike generic coding assistants, it understands your Snowflake data, compute, governance, and operational semantics, translating complex data engineering and agent-building tasks into natural language workflows - helping teams deliver production-ready outcomes faster.
But here's the tension: the faster you can build and deploy agents, the sooner the observability gap opens and the wider it gets. Cortex Code compresses weeks of development into days. That's powerful. It also means more agents, deployed faster, with less time to instrument them properly.
Speed without visibility is just faster risk.
Snowflake Intelligence is, by design, open and accessible - any employee, any question, any agent. That's the promise. But it's also precisely why monitoring becomes non-negotiable. The more democratized the access, the more unpredictable the usage patterns. The more agents you deploy, the more surfaces there are for cost overruns, quality drift, and silent failures. Snowflake Intelligence doesn't create these problems but its scale and accessibility amplify them faster than any tool that came before it.
The Four Things You Need to See - And What Happens When You Can't
At SBI, as a Launch Partner for Snowflake Intelligence, we built a monitoring layer specifically to close this gap. It operates across four control planes.
I. Cost Guardrails - Visibility Before the Surprise
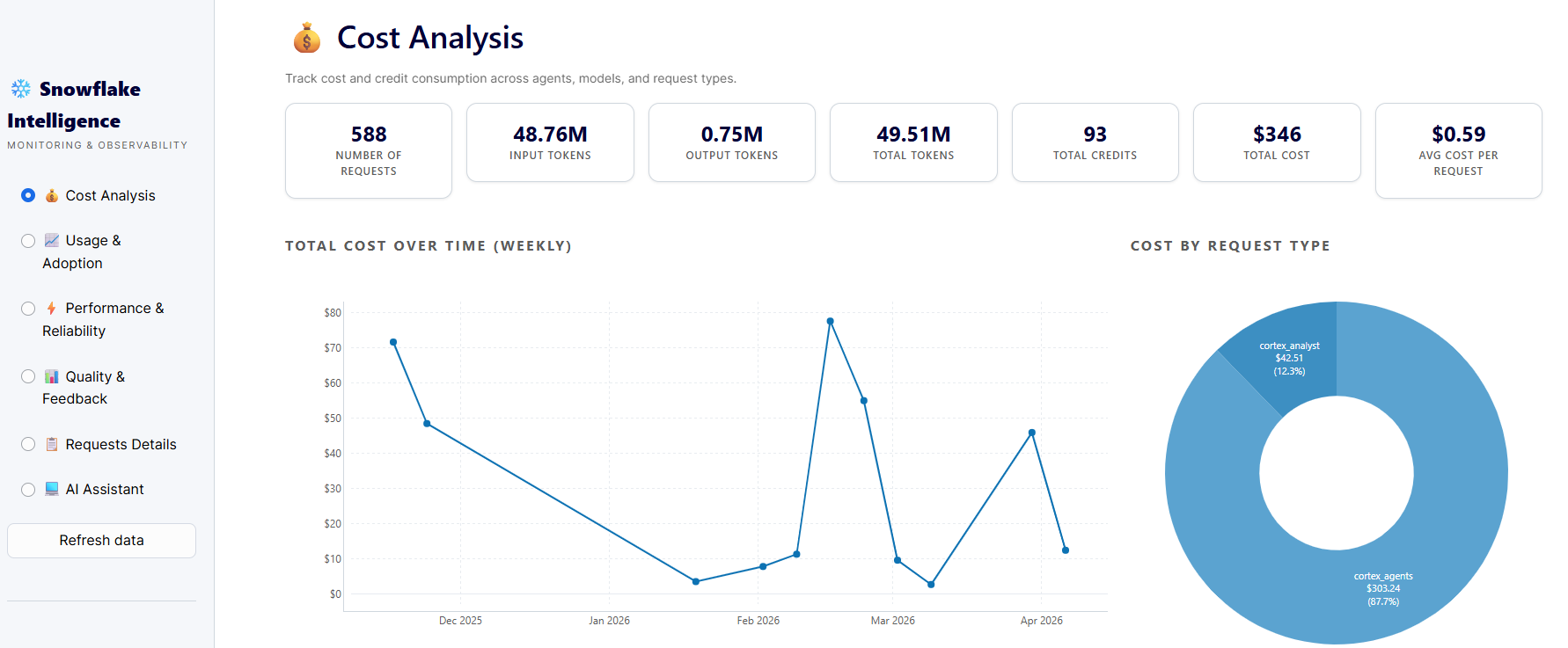
AI credit consumption is deceptively hard to track. Unlike a SaaS subscription with a fixed monthly invoice, consumption-based AI pricing is dynamic. It scales with usage, with query complexity and with the number of agents running in parallel. Left unmonitored, it compounds silently.
The failure mode is always the same: no one realizes there's a problem until the end-of-month reconciliation. By then, a single agent running in a loop, or one power user firing hundreds of unconstrained queries, has already generated costs that are impossible to attribute after the fact.
Meaningful cost visibility means knowing, at any moment, who is consuming what, through which agent, at what rate. It means spotting when a specific query type is disproportionately expensive, or when daily spend is trending toward a threshold before the threshold is reached.
But tracking alone isn't enough. You need guardrails that act. When a user approaches their limit, send a reminder. Not a hard stop, just a nudge. When they cross it, block further queries and notify the right person. When a team is trending toward overage mid-month, trigger an alert before the damage is done. When an agent's average cost per query suddenly spikes, flag it immediately - something in the underlying logic may have changed.
The goal isn't to restrict usage. It's to make cost visible enough that the right people can make informed decisions - and to ensure that no single user, agent, or misconfiguration can silently drain the budget.
II. Usage & Adoption - The Metric That Tells the Real Story
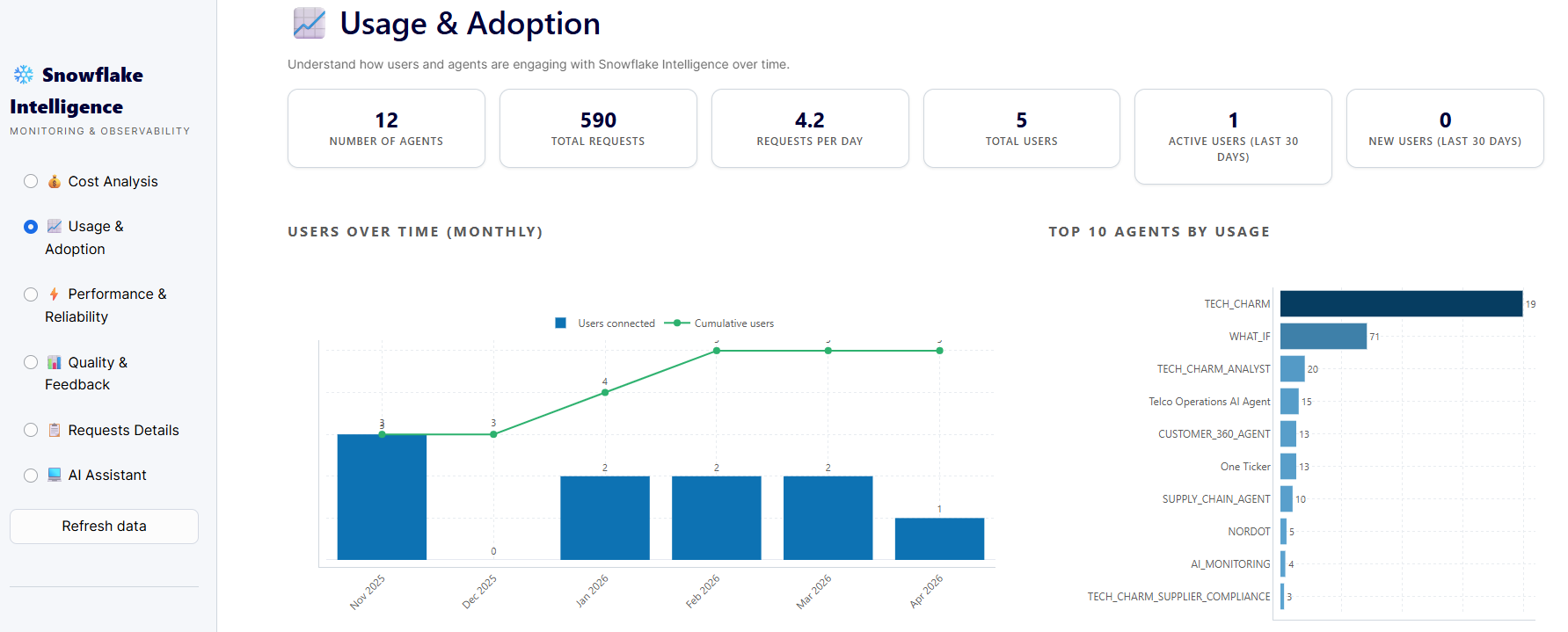
Deployment is not adoption. An agent that was launched with fanfare three months ago may have ten active users today. Without usage data, you genuinely cannot tell the difference between a thriving deployment and a slow, silent failure.
The signals that matter go beyond raw query counts. Are users coming back the next day - or was the first session also the last? Are they engaging in multi-turn conversations, going deeper into the data, or asking one surface question and leaving? Is usage concentrated in one team while others ignore the agent entirely? These patterns tell you things that no status report ever will.
The analysis unlocks decisions you can't make any other way. A drop in return rate after week two points to a retention problem - likely rooted in quality. Adoption concentrated in one function while others disengage suggests a communication or training gap. Query topics clustering around questions the agent consistently struggles with become your next development priority.
Usage data is not just a health metric. It's a product roadmap in disguise - and the clearest signal you have of whether the AI is actually changing how people work, or just sitting there looking impressive in a demo.
III. Quality & Feedback - Catching What Slips Through
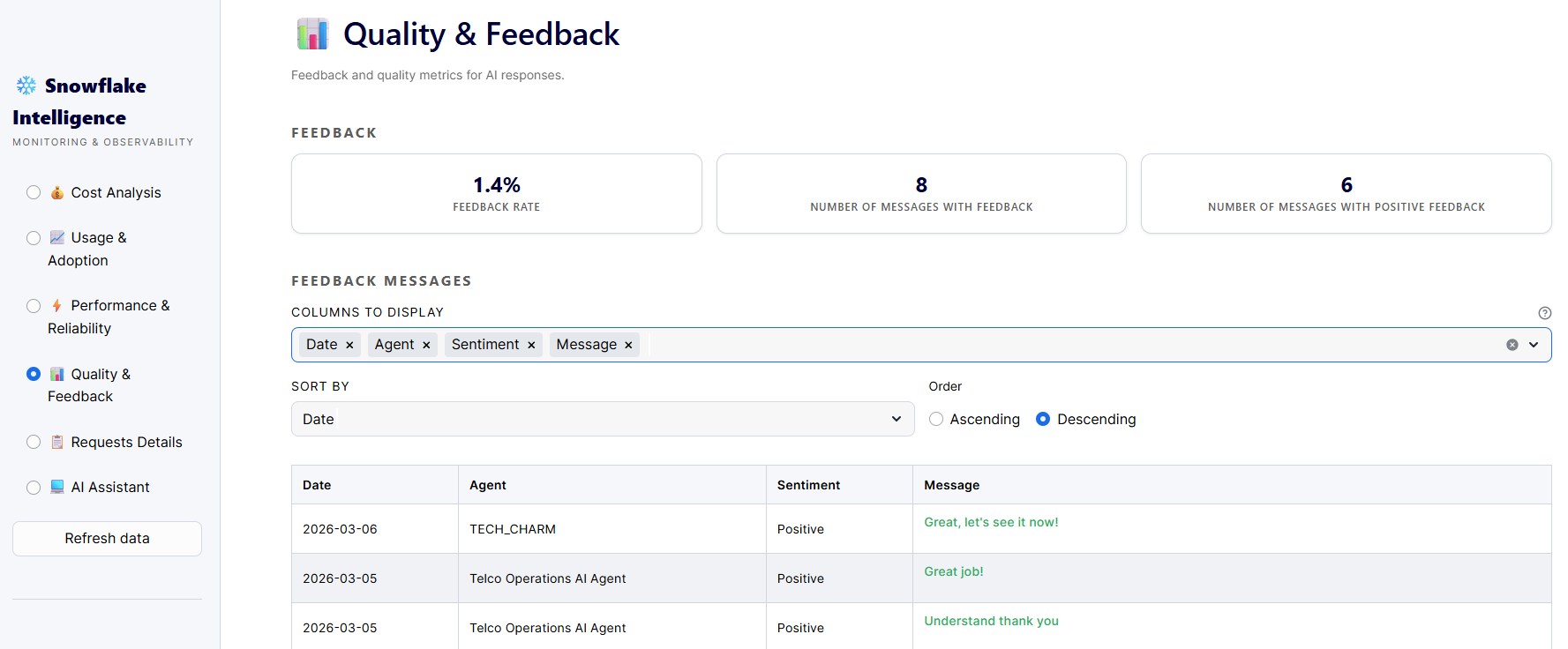
Wrong answers in production are not always loud. An agent that is 80% right, 20% wrong will erode trust slowly and invisibly - until one day the business has quietly stopped relying on it, and no one quite remembers the moment it lost their confidence.
The challenge is that most feedback mechanisms are passive. A thumbs-down button captures explicit dissatisfaction, but most users don't bother. They just stop asking. By the time you notice the drop in usage, the quality problem has been compounding for weeks.
Real quality monitoring means closing that gap - tracing every piece of negative feedback back to its source, understanding whether the agent drifted from the data it cited, whether it answered an adjacent question instead of the actual one, and whether the pattern is isolated or systemic. It means building a verified library of the most common questions with known-good answers locked in - so the agent isn't reinventing the wheel every time, and so your most critical business questions have a guaranteed floor of accuracy.
Every piece of negative feedback is a triage ticket. The teams that treat it that way build agents that get demonstrably better over time. The ones that don't wonder why trust never quite takes hold.
IV. Performance & Reliability - Knowing Before Your Users Do
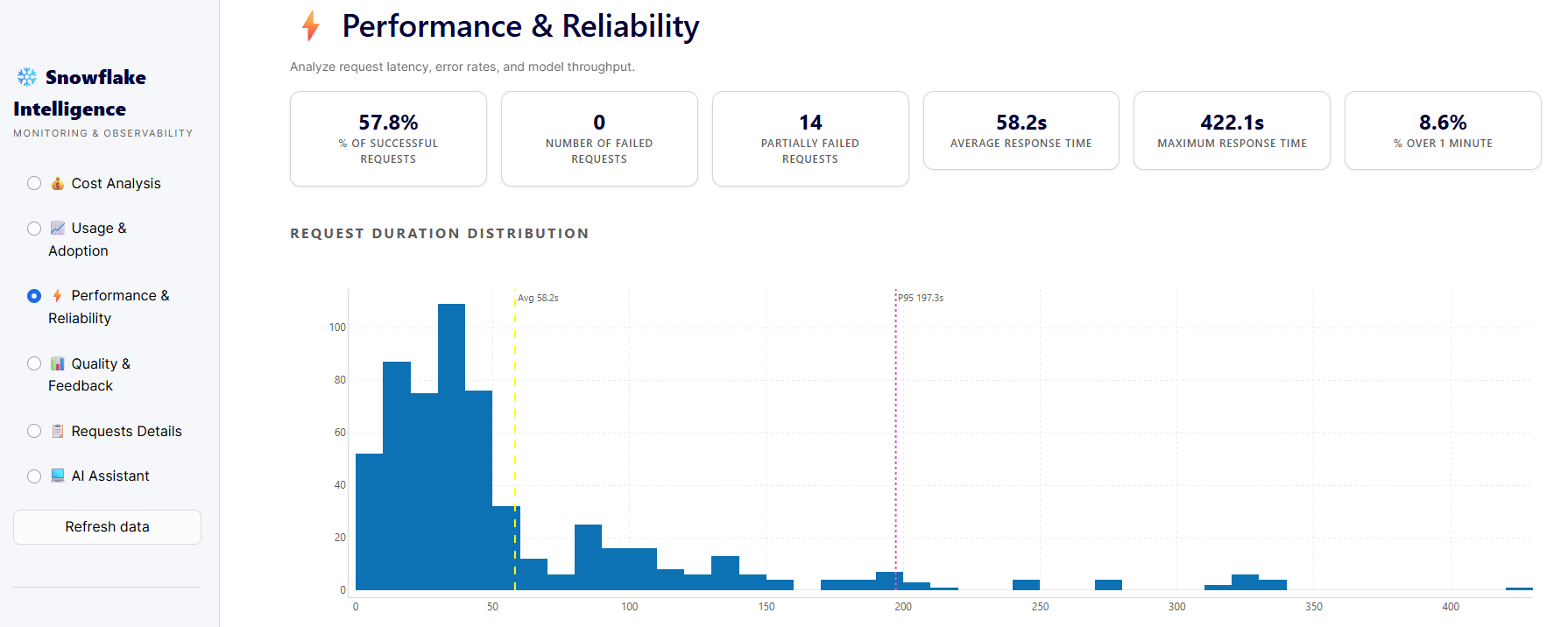
Latency and reliability issues don't announce themselves until they are already a user experience problem. And in enterprise AI, a slow agent isn't just frustrating, it's a trust signal. Users interpret latency as unreliability. They start to wonder whether the agent is actually working, or just stuck. After enough slow responses, they stop using it.
The subtler risk is drift. Performance doesn't always degrade suddenly - it erodes gradually, as data volumes grow, schemas change, or model updates introduce friction that accumulates invisibly. By the time it's noticeable, it has already been costing you for weeks.
What separates teams that catch these issues early from those who don't is proactive alerting with teeth. Not a dashboard someone checks on Fridays, but thresholds that trigger notifications the moment response times cross a defined ceiling, failure rates tick above baseline, or a specific tool call starts behaving differently than it did last week. The goal is simple: you should always find out from your monitoring system, never from a user complaint.
Reliability isn't a feature. It's the precondition for everything else.
The Teams That Win Won't Just Build the Smartest Agents
There is a pattern emerging among the organizations getting real, sustained value from enterprise AI. They are not necessarily the ones with the most sophisticated models, or the largest budgets, or the most agents deployed. They are the ones who treat operational discipline as a first-class concern, who instrument before they scale, who define what "working" means before they ship, and who build the feedback loops that make their agents genuinely improve over time.
In 2026, the challenge won't simply be getting agents into production. Leaders will need to build the discipline around them - establishing verification frameworks, defining where human oversight begins and ends, and maintaining observability so every agent action can be audited, explained, and trusted.
The four control planes described here - cost, adoption, quality, performance - are not Snowflake Intelligence specific problems. They are the universal conditions of running any intelligent system in production, on any platform, at any scale. The tooling differs. The discipline does not.
Snowflake Intelligence gives you the platform. Cortex Code gives you the velocity. Observability gives you the right to keep running.
The organizations that come out ahead won't be the ones who moved fastest. They'll be the ones who moved fast and could see clearly and who treated operational discipline not as a cost of doing AI, but as the foundation of it.
That's the bar. It's worth building for.
Ready to take your AI agents beyond deployment? Talk to our team, we'll help you build the operational layer that keeps them running reliably.


